充分的了解搜索引擎算法才能真正掌握seo优化技术,所以在一开始的seo技术的学习当中就要不断的由浅入深的去建立这方面更加专业的认知。在seo基础学习当中如果不去了解和认识搜索引擎,确实是无法通过纯白帽seo来完成一个网站的优化,今天小凯seo博客和朋友们分享一下搜索引擎算法中TF-IDF是什么意思,以下内容转载自百度百科。
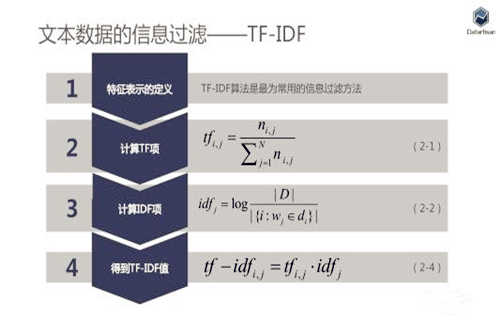
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处. 在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)
TFIDF算法是建立在这样一个假设之上的:对区别文档最有意义的词语应该是那些在文档中出现频率高,而在整个文档集合的其他文档中出现频率少的词语,所以如果特征空间坐标系取TF词频作为测度,就可以体现同类文本的特点。另外考虑到单词区别不同类别的能力,TFIDF法认为一个单词出现的文本频数越小,它区别不同类别文本的能力就越大。因此引入了逆文本频度IDF的概念,以TF和IDF的乘积作为特征空间坐标系的取值测度,并用它完成对权值TF的调整,调整权值的目的在于突出重要单词,抑制次要单词。但是在本质上IDF是一种试图抑制噪音的加权 ,并且单纯地认为文本频数小的单词就越重要,文本频数大的单词就越无用,显然这并不是完全正确的。IDF的简单结构并不能有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能,所以TFIDF法的精度并不是很高。
此外,在TFIDF算法中并没有体现出单词的位置信息,对于Web文档而言,权重的计算方法应该体现出HTML的结构特征。特征词在不同的标记符中对文章内容的反映程度不同,其权重的计算方法也应不同。因此应该对于处于网页不同位置的特征词分别赋予不同的系数,然后乘以特征词的词频,以提高文本表示的效果。
TF-IDF 模型是搜索引擎等实际应用中被广泛使用的信息检索模型,但对于 TF-IDF 模型一直存在各种疑问。本文为信息检索问题一种基于条件概率的盒子小球模型,其核心思想是把“查询串q和文档d的匹配度问题”转化为“查询串q来自于文档d的条件概率问题”。它从概率的视角为信息检索问题定义了比 TF-IDF 模型所表达的匹配度更为清晰的目标。此模型可将 TF-IDF 模型纳入其中,一方面解释其合理性,另一方面也发现了其不完善之处。另外,此模型还可以解释 PageRank 的意义,以及 PageRank 权重和 TF-IDF 权重之间为什么是乘积关系。